
From Quality of Experience to Quality of Service for a communication network
Nowadays, most Service Providers (SPs) are interested to see whether or not Customers are delighted with the services being provided to them. And many Customers want to know if they got for what they pay. Therefore, to meet Customers’ expectations, SPs need to permanently measure the current level of service quality through a standardized and consolidated quality monitoring process.
Basic monitoring methods measure Quality of Service (QoS)-related network level parameters like packet loss, jitter, and throughput. These basic monitoring tools, sometimes based on a standard like RFC 2544, do not explicitly consider the users’ perception, so they can be considered technology-centric rather than user-centric.
In this article, we will try to provide tools, guidelines, and insights to whom must deal with topics such as service assurance, Service Level Agreement (SLA) management as well as stability in the network (i.e. signaling/synchronization as in the mobile access network)
What is the Quality of Service (QoS) and the Quality of Experience (QoE) of communication services? This simple question has been the topic of various studies and research. As an example, the standardization sector of the International Telecommunication Union (ITU-T) has a dedicated study group (SG12) working on “Performance, QoS and QoE”.
The purpose of all these activities on Quality of Service is to define clear and accurate measures for the quality perceived by end-users (i.e. the QoE) that are required to bridge the gap between the offered end-to-end service and the underlying technology.
Matching subjective opinions and experience of users with measurable objective network parameters or Key Performance Indicators (KPI) is a quite tough task due to the complexity of the technical reality of whatever communication service.
As a result of this aspect, various standards have defined frameworks, end-to-end service metrics, and measurement methods. What becomes clear from all these standards is that there is no stable set of them covering the services in an undisputed way.
Moreover, the standards are subject to change, improvement and refinement leading to a continuous redefinition of tools and methodologies for network quality estimation.
Two facts are quite clear to all:
- Starting from the assumption that QoE is directly related to the network performances, the challenge for a Service Provider is to have the right set of tools and processes to map the QoS at the network level to the QoE at the user and session levels having the ability to control the network parameters that affect QoS.
- Another important point to note is that measurements in individual nodes may indicate acceptable network QoS, but end users may still be experiencing unacceptable QoE. That means an E2E evaluation of network performance at the different protocol levels is crucial for low performance detection.
The challenge for a Service Provider is to have the right set of tools and processes to map the QoS at the network level to the QoE
ETSI provides a more detailed QoS framework based on the more general ITU 800 series. This framework clearly distinguishes between the different phases of the customer experience and suggests that the QoE cannot depend on the behavior of a single element of the communication channel.
The phases of ETSI framework on which QoE depends on are:
- Network Availability. Probability that the services are offered to a user via a network infrastructure.
- Network Accessibility. Probability that the user performs a successful registration on the network which delivers the service. The network can only be accessed if it is available to the user.
- Service Accessibility. Probability that the user can access the service he wants to use. A given Network. Accessibility is a precondition for this phase.
- Service Integrity. This describes the Quality of Service during service use and contains elements like the quality of the transmitted content, e.g. speech quality, video quality or number of bit errors in a transmitted file. The Service Integrity can only be determined if the service has been accessed successfully.
- Service Retainability. It describes the termination of services (in accordance with or against the will of the user). Examples for this are all kinds of cut-off parameters, e.g. the call cut-off ratio or the data cut-off ratio. Again, a previously performed successful service access is a precondition for this phase.
An E2E evaluation of network performance at different protocol level is crucial for low performance detection.
TRAFFIC CLASSIFICATION AND KPIs
As Ethernet continues to evolve as the transport technology of choice, networks have shifted their focus from purely moving data to providing entertainment and new applications in the interconnected world. Ethernet-based services such as mobile backhaul, business and wholesale services need to carry a variety of applications, namely voice, video, e-mail, online trading and others.
These new applications impose new requirements on network performance and on the methodologies used to validate the performance of these Ethernet services.
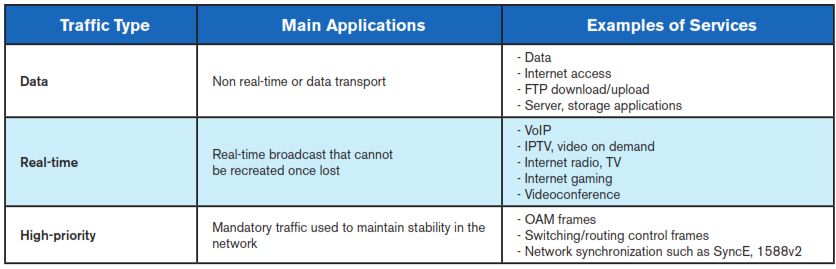
To assure QoS, Service Providers need to properly configure their networks to define how the traffic will be prioritized in the network. This is accomplished by assigning different levels of priority to each type of service and accurately configuring network prioritization algorithms.
This allows to assure specific KPIs that change according to traffic characteristics that indicate the minimum performance of a particular traffic profile.
Typical KPIs include measurements concerning:
- Bandwidth
- Frame Delay (Latency)
- Frame Loss
- Frame Delay Variation (Packet Jitter)
Each application is more sensitive to one or more of these KPIs: for example data traffic is not so sensitive to jitter such as real-time one, but it is more sensitive to frame loss than real-time traffic because missing packets can destroy the whole information integrity while the same issue in a video service can generate some picture impairments (i.e. picture freezing, blocketization etc) limited to the packets lost.
In order to mitigate the effects of variable network performances, specific software/protocol or hardware solutions can be used such as re-transmission for data service or buffer capable to store a certain quantity of video and voice packets.

RIGHT ATTITUDE, WRONG TOOLS
Actually, many Service Providers use RFC 2544 in order to validate the performance of their network. The reasons were related to the fact that RFC 2544 has been the most widely used Ethernet service testing methodology.
Since RFC 2544 is able to measure throughput, burstability, frame loss, and latency, and because it was the only existing standardized methodology, it was also used for Ethernet service testing in the field.
However, RFC 2544 was designed as a performance tool with a focus on a single stream to measure the maximum performance of a Device Under Test (DUT) or Network Under Test (NUT) and was never intended for multiservice testing.
So, even if RFC 2544 provides key parameters to qualify the network, it is no longer sufficient to fully validate today’s Ethernet services. More specifically, RFC 2544 does not include all required measurements such as packet jitter, QoS measurement and multiple concurrent service levels.
RFC 2544 was designed as a performance tool with a focus on a single stream and does not include all required measurements such as packet jitter, QoS measurement and multiple concurrent service levels.
Additionally, since RFC 2544 requires the performance of multiple, sequential tests to validate complete SLAs, this test method takes several hours, proving to be both time consuming and costly for operators.
With networks evolving, the standard adopted for performance monitoring needs to address different types of network configurations and ensure that quality is maintained across networks with multiple streams and with different policing parameters.
Having performance monitoring tools able to validate link quality not only at subscription stage but periodically in order to prevent any fault or service degradation and/or simplify the network troubleshooting is technically strategical for Service Provider’s churn rate reduction and customers’ satisfaction improvement.
On the other hand, the chance to check the quality of service offered through a smart web dashboard is also valuable for the customer because he can verify if the minimum performance levels assured by SP in his binding contract (i.e. SLA) for network services with him are really guaranteed.
The ITU-T Y.1564 standard has been specifically created to test basic services on packets and to resolve gaps in the RFC 2544 standard. ITU-T Y.1564 is intended for multiservice testing to measure the maximum performance of the DUT or the NUT.
ITU-T Y.1564 standard is a set of procedures that test the ability of Ethernet-based services to carry a variety of traffic (voice, data, and video) at defined performance levels. In particular, it is aimed at addressing limitations of legacy RFC 2544 test procedures, especially for SLA.
AN APPROACH TO NETWORK QUALITY ASSESSMENT
Even if ITU-T Y.1564 standard contains more testing measurements than the RFC 2544, without the appropriate training/education it could be daunting for a field technician to adopt it. The result is that field technicians may opt to stay with RFC 2544 to test Ethernet services, instead of testing with the correct and up-to-date methodology-Y.1564.
Not only. Performance monitoring evaluation should be a stable platform fully integrated into a data network so that reports could be automatically produced without involving any human support with consistent savings and quality improvement onto operations.
Given the above concern, a combination of active and passive as well as client-side and network-centric probes seems the most promising for a quality monitoring system that delivers accurate predictions for both real users of the service and a general overview of service quality from sampling points in the network.
Network reference model for a performance monitoring platform
There are two basic categories of probes used in monitoring systems, as described in the following:
- Active probes: they actively initiate a service connection or send and receive data to measure quality for a certain timeframe.
- Passive probes passively measure network traffic passing through the network.
An active probe could be implemented, for example, to set up a test VoIP phone call to another active probe. With active probes, no real users are involved in the measurement process but they resemble the user scenario as closely as possible. Due to their complexity, using active probes for monitoring purposes is mostly more difficult than passive probes in terms of set-up and maintenance. Moreover, active probes cannot be placed at every possible location in the network so an operator has to choose representative points in his network to place these probes at, in order to have a good overview of the quality for their entire customer base.
A passive probe is placed all along the delivery chain, at the server-side, in core networks, in the access network, in the home network, or at the user’s terminal. When they are used in network-centric locations, passive probes can potentially measure a large number of parallel streams. In a simple form, passive probes can measure KPIs like jitter, packet count, packet loss for any given stream. However, they can also make more fine-grained analyses related to higher levels of data, e.g., HTTP contents.
Passive probes can also be used in combination with other test systems in order to perform quality calculations that could not be implemented on the test device itself (for example because its software cannot be changed or its software platform does not allow for capturing network data).
Since they often need to monitor more than one stream at the same time, passive probes dos not typically provide the most in-depth analyses. There is a trade-off between accuracy and the number of measurements that can be performed since practically, not every packet stream can be inspected at a certain depth.
With regard to monitoring points, probes can be categorized into two main classes. The first category is network-centric probes. These probes in the form of network appliances are either deployed on network elements such as routers or switches or come in the form of dedicated hardware attached to other network elements.
The second class is the client-side probes. These probes can be software agents deployed on user devices or dedicated devices placed at user locations. What differentiates network-centric from client-side approaches therefore is the location in the delivery chain. Typically, client-side probes describe measurement points at or behind a user’s home gateway.
In Figure 3, a simplified schema of a network is shown. Here we can see the possible locations for placing probes, such as the CDN, the core ISP network, the access network, or at the customer’s home. In the latter case, we would refer to client-side probes.
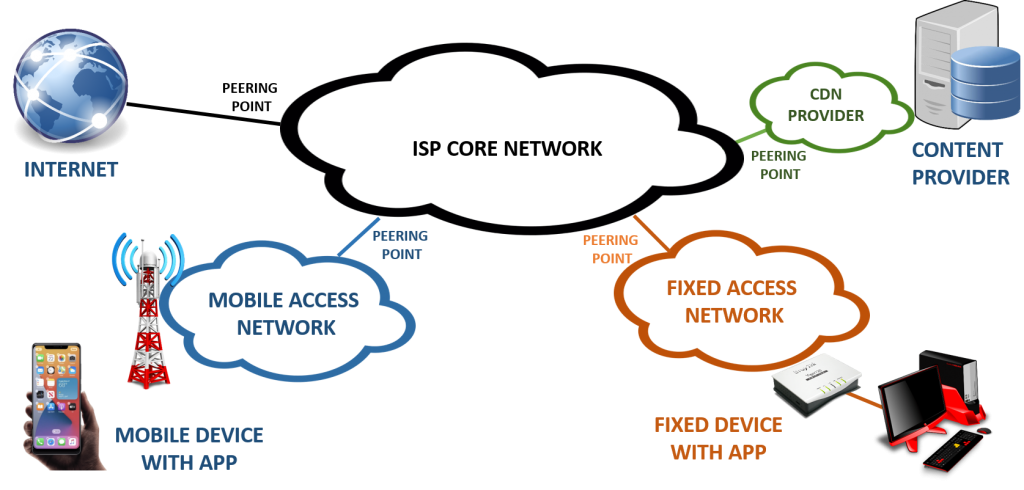
Furthermore, we can distinguish probes according to who owns them, or where the quality is monitored (see Figure 3):
- Content-provider domain: The supplier of the content, that is, the over-the-top provider (e.g. YouTube, Netflix or Amazon)
- Service-provider domain: The supplier of the service itself, which could be a Content Distribution Network provider (e.g. Akamai)
- Network-provider domain: Typically the ISP itself, that is, the supplier of the access network.
The placement of probes touches two important aspects in quality monitoring scenarios:
- Privacy vs. Context Data: Client-side probes, especially when implemented in real user devices, have access to much more information than what is available in transmitted network streams. For example, a mobile device knows about the user’s location and surroundings, although it is not necessarily visible on the transmitted network data. Naturally, privacy concerns limit monitoring systems from collecting all user context data, although it would be required for a more accurate prediction of QoE for any given service. But even in network-centric aspects, privacy concerns play a large role.
- Encryption: When probes are placed on core network elements, they are typically blind to certain application data that is transmitted over encrypted channels. Encryption (e.g., in the form of HTTPS or RSTP) makes any data sent over the TCP level inaccessible to the network provider, since the secure data channel is set up between the server and client end points. Therefore – also given the increase in the adoption of encryption over the last years – network-centric probing approaches will become increasingly blind to the data being transmitted. For some use cases such as video or audio transmission, missing knowledge about used codecs or lost packets will make it virtually impossible to provide accurate quality predictions.
Given the above concerns, a combination of active and passive as well as client-side and network-centric probes seems the most promising for a quality monitoring system that delivers accurate predictions for both real users of the service and a general overview of service quality from sampling points in the network.
Real and Virtualized Monitoring
Recently, endeavors to simplify network management have increased, with two main innovations being Software-Defined Networks (SDN) and Network Function Virtualization (NFV).
The main goal of SDNs is to decouple the network control and data planes which brings programmability and centralization control to computer networks. Therefore, it simplifies network management.
Nowadays, SDN has attracted significant attention from both academia and industry. ForCES and OpenFlow are the two main SDN technologies, which are implemented and brought SDN from academia to the actual market.
NFV is a novel procedure to transfer network functions from hardware devices to software applications. Therefore, the goal of this concept is to decouple network function from hardware appliances without any impact on functionality. In the field of performance improvement and network simplification, this concept is highly complementary to SDN. These two topics are independent of each other but are mutually beneficial.
With current network technologies, we can use virtual probes for monitoring and testing of applications and networks. A virtual probe is a test entity that enables addressing various aspects of performance management across the life cycle of business-critical service delivery using NFV, cloud- and SDN-based infrastructure.
The virtual probes are able to work as virtualized test functions on any virtualization-capable network element (such as routers and switches). The use of virtual probes is reducing the cost of the hardware and the complexity of the network.
Furthermore, they are flexible, thus they can be placed in virtual environments easily unlike the real probes. One important advantage of these is that via a virtual probe, all the interfaces are visible to it. Thus, it is able to extract appropriate information for customer experience management. The network can be provisioned efficiently and the customer experience can be improved.
QoE modeling
As already stated above, QoE can be affected by technical or non-technical factors. QoS is represented by KQIs and is what end-users experience directly and, finally, KPIs represents the performance of network devices not perceivable by end users, so QoS best reflects QoE.
KQIs represent external indicator of network quality, ideal to compare different solutions/technologies on a statistical basis being essentially operator/vendor independent. Unfortunately cannot be reported from the network itself so they require some kind of field testing.
KPIs represent internal indicator of network quality because they are part of network performance and based on network counters. They are essential for operation, maintenance and can be easily reported/audited but they are completely meaningless when out of context.
Due to that, QoE estimation can be done by mapping KPIs of the network and services to KQIs as described by many standards. The mapping relationship defined can allow Service Providers ,as well as OTTs and users, to evaluate in advance the expected quality for service request or to monitor the performance in order to get an alarm on quality degradation.
As said above, different services have different standards of measurement. The TMF has defined, for example, KQIs for VoIP and IPTV (such as voice quality, image quality, synchronization of voice and image, delay, and response speed) while ETSI has described a framework for QoS definition, KQI and trigger points for different type of services (Web, Mail, FTP etc).
Now, each KQI is affected by different network nodes performances or KPIs. Let’s consider two examples thereof:
- Web browsing. If the web page loading time is good, it also implies that the KPIs network like throughput, DNS functions and latency are quite good. Of course if the server has poor performance this will have an impact on customer’s experience related to that specific website while if the customer has a device with some hardware or software problems, the detection of these issues is very easy if KPIs network listed above are within acceptable range
- IPTV services. If the quality of service is good (i.e. good picture and audio quality, good lip-synch, no image freezing or blocking) the underlying IP packet transport network KPIs such as bit error rates, packet loss, jitter, latency, etc. are all good enough to deliver a good end-user experience.
Without going into details, it is possible to categorize any services according to the required KQIs and, through a calculation function, get the related KPI thresholds below that network performance affect the QoS.
CONCLUSIONS
Over the last decade, the use and diversity of multimedia applications have extended tremendously. Traditional approaches to QoS/QoE monitoring may, at some point, not be applicable anymore, for example, due to architectural constraints.
Also, it has been understood that a real prediction of QoE is only possible with access to detailed indicators from the applications sent over the network, which are not always available.
In this article, we first described how QoE is typically assessed according to standards frameworks by comparing the different approaches used by Service Providers for performance evaluation.
Then we moved our focus onto a reference model for a performance monitoring platform, considering the constraints and the opportunity related to data security and network virtualization, and, last, introducing the need for a correct QoE modeling of different applications within the performance monitoring platform for a good match between network performance indicator (KPI) and quality of service (KQI).
Do you want to learn more? Please contact us here
ABOUT OPNET
OPNET Solutions is a company based on highly skilled people with decades years of technical and managerial experience in ICT, Telco and Energy industries and technologies.
Our purpose is to provide, to big and small companies, high-end tools and resources to empower and grow their business.